Sivaraman Subramaniam
IT incident management is a practice, process as well as tools, which will enable the IT teams to bring a failed IT service to normal as quickly as possible after a disruption. It ensures critical systems and applications are always online and available for customers. IT incident management is an area of IT service management (ITSM), helps keep an organization prepared for unexpected hardware, software and security failings, and it reduces the duration and severity of disruption from these events.
A focus on IT incident management processes and established best practices will minimize the duration of an IT incident and shorten recovery time of IT Service, and it can prevent future issues. Understanding the foundations of incident management and infusing the fundamentals will create a polished and swift response process—and, more importantly, keeping services “always on” makes your customers happy.
Companies tend to gravitate toward different types of incident management processes. For IT Incidents in specific, most successful companies adapt to an established ITSM framework, such as IT infrastructure library (ITIL) or COBIT, or be based on a combination of guidelines and best practices established over time. Organizations who follow ITIL or ITSM practices may use the term major incident management for this instead.
The Importance of IT Incident Management
Whenever a disruption to IT service occurs, in turn it impacts the related business services. Many organizations report disruption of IT services costing more than $300,000 per hour, according to Gartner. For organizations, where most customer interactions happen over the web, that number can be dramatically higher.

Incidents are generally categorized by low, medium and high priorities. Low-priority incidents do not interrupt end users, who typically can complete work despite the issue. Medium-priority incidents are issues that affect end users, but the disruption is either slight or brief. High-priority incidents, however, are issues that will affect large amounts of end users and prevent the proper functioning of a system.
Assigning the right priority , severity , impact scope and description are as important as resolving the Incident itself. Not having proper process and training jeopardize the entire IT incident Management Practice.
IT Incident Management helps Devops, SecOps, IT Operations and MIM (Major Incident Management) teams with reliable methods to prioritize incidents, assign severity, get to resolution faster, and offers following functionalities
- Identifying, logging and categorizing an Incident, so that proper teams can be identified to recover failed IT Service.
- Provide a situational awareness and common Operating picture of IT Services across the organization.
- Relation between affected IT services and underlying Business Service Mapping.
- Communicate clearly to customers, stakeholders, service owners, and others in the organization.
- Collaborate effectively to solve the issue faster as a team and remove barriers that prevent them from resolving the issue.
- Continuously improve to learn from these outages and apply lessons to improve a service and refine their process for the future.
Lifecycle of IT Incident
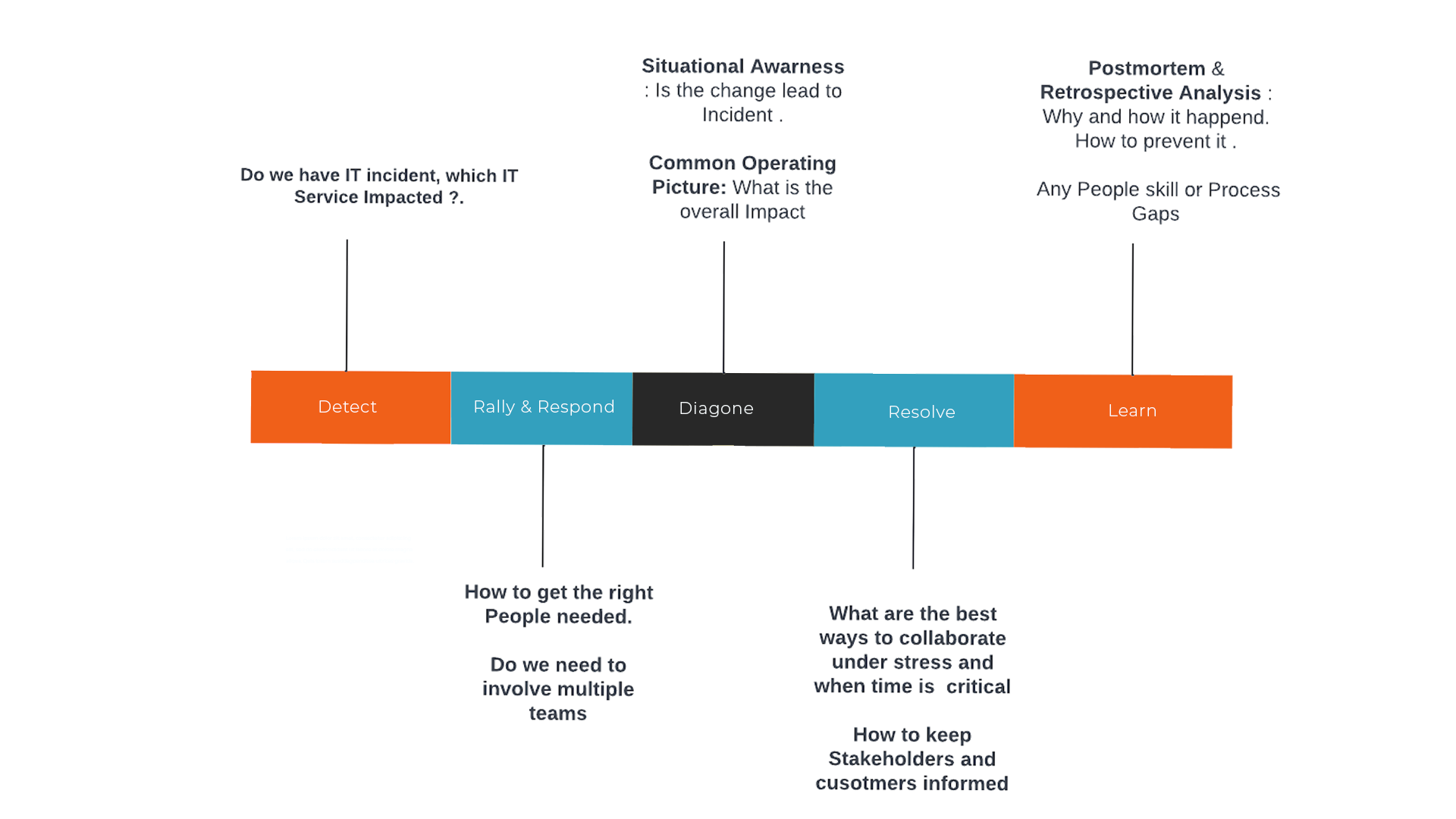
Detect :
NOC, SOC and MIM teams at your company can become aware of incidents in many ways. They can be alerted by Devops Monitoring tools , through customer support cases, or by observing it themselves. Identifying the problem and detecting the true Incident is the real challenge as all the above mentioned methods do generate a huge volume of data, this is where Event Management helps companies. Once the teams realize there is an incident, the first step the team takes is logging an incident ticket, with description , severity and priority. Metrics such as MTTI (Mean Time to Identify) incidents are important SLA to track.
Next step is to figure out whom to assign the Incident.
Rally & Respond :
This is a very important stage in the IT Incident Management process, identifying the right team, right person with the appropriate skills to assign the Incident and notifying them on the right communication channel. Most organizations take an average of 30 mins to identify and rally the right people due to either manual Incident alerting process or siloed tools for logging the Incident in one tool and notifying the right person via a different tool. Manual or semi or solid automation of IT Incident response increase MTTR (Mean Time To resolution )
An automated incident response solution like Zapoj IT Incident Management helps organizations to orchestrate the identifying right oncall personnel and notifying him/her on the right communication channel to resolve incidents faster and reduce your mean-time-to-resolution (MTTR).
Diagnose :
Once the incident is assigned, oncall staff personnel can begin investigating the type, cause, and possible solutions for an incident. This is where situational awareness of what had happened and happening now with a specific IT Service involved as part of the Incident helps teams to narrow down the root cause of the problem. Common Operating Picture provides which down and upstream service might be already impacted or soon going to be, so that oncall personnel can request other teams to be notified or escalated within his team. After an incident is diagnosed, you can determine the appropriate remediation steps.
Resolve :
Once the right teams join and a plan of attack has been formulated, the incident resolution phase begins. Here Incident commander role , determine what needs to be shared with the public, stakeholders , and customers. Ability to share the relevant information with each of the involved parties improves customer satisfaction and compliance. Critical Event Management Platform like Zapoj, helps Major Incident Manager quickly identify the impacted customers, launch Mass Notifications , provide ChatOps & Video conferencing features to Incident Responders and Status Pages to Stakeholders.
Closing incidents typically involves finalizing documentation and evaluating the steps taken during response. SLA metrics to be tracked include MBTF (Mean Time Between Failure).
Learn :
Learning from recent and historical incidents is arguably the most important step in the IT incident Management process. It’s in the aftermath that your team is able to look and see what went well or what didn’t go so well, and what you can do to prevent things from happening again. Incident post-mortems and analytics are a great way for teams to continuously learn and serve as a way to iteratively improve your infrastructure and IT incident management process.
Roles In IT Incident Management
Every organization typically has their own custom roles and responsibilities, below are some of the most common IT incident management roles:

- End user : This is the client or Customer who usually experiences the first sign of an outage or disruption and will flag it to the customer support case.
- Customer Service Desk : Typically the first point of contact when there is a customer case involving IT service and initiates the IT incident management process requesting an IT incident ticket.
- IT Incident Manager : A key stakeholder in the IT incident management process that drives the entirety of the lifecycle from Response to Resolution.
- NOC Service Desk or IT Operations : Composed of technicians with primary knowledge around major incidents involving applications, infrastructure, and systems management.
- IT Incident Responders (Devops , Secops, App Teams , DBA’s ) : Specialist technicians that have advanced knowledge in extremely specific regions of the company’s infrastructure and applications. Usually these professionals are brought in for complex incidents, maintenance and remediation
- IT Incident Operator : This person typically moderates the incident communications between response teams, customers and Key stakeholders.
Choosing IT Incident Management Software
For 21st century businesses are “always one”, be it a small or large or multi national corporation, the cost of IT downtime can mean thousands of dollars lost revenue, negative customer sentiment, or hundreds of lost customers. These consequences mean IT Executives (CIO , CTO) must maintain and manage cloud and on-premises infrastructure, applications, APIs, and containers—all while rolling out enhancements and upgrades in near real time to meet ever-changing customer demands.
There are many siloed or traditional IT service management (ITSM) tools to choose from when it comes to implementing your IT incident management processes, and they all have varying features. To remain competitive, it’s critical that you ensure the following features are met.
management processes, and they all have varying features. To remain competitive, it’s critical that you ensure the following features are met.
Here are important features to look out for
- Ensure your IT incident management platform is always up when your IT is down.
- Does it support an IT Service based approach rather than IT Team based approach?
- How easy your teams can integrate their preferred Monitoring, security , and change management tools.
- Does it support Automated Incident alerting and response for your IT response teams.
- Does it provide real-time situational awareness into incidents and overall health of your IT services?
- Does it have AI, to reduce the number of Incidents or convert alerts into Incidents.
- Does it offer important collaboration features like inbuilt Chatops and Conferencing.
- Does it offer Customer and Key stakeholders notifications to update status.
- Can you gain actionable insights from data (IT Services, Incidents, Teams, On Call schedules, Alerts).
- Finally , the cost to operate and own the software.
Learn more about Zapoj IT Event Management and the automated Major incident Management, which encompasses everything from Detect, to resolve – to learning and prevention to support IT teams as they move towards owning their code in production.